
What Is Behind The DeepSeek Hype?
The tech industry have been rocked by the DeepSeek R1 model since its early January 2025 release. Is the hype justified? This series of posts will examine the technology behind the R1 model.

DeepSeek R1, a new open-sourced large language model released by a Chinese startup in January 2025, has garnered significant attention. Developed on a tight budget and timeline, it rivals the industry's top LLMs. While concerns persist around security, safety, veracity, and accuracy, the technical innovations behind the model are undeniable. This tri-part series will focus exclusively on exploring these technical advancements.
This is the first blog in a three part series. The other two posts are at Model Architecture Behind DeepSeek R1 and DeepSeek's Model Training Methodology.
First Some Context
To gain a better understanding of DeepSeek's innovations and contributions, it is crucial to first examine the broader context surrounding the rapid rise of Large Language Models (LLMs) and the current industry practices and trends. The way for the GenAI revolution has been paved by a long list of innovations in deep learning and NLP research over the past few decades. However, for sake of time, we will keep our highly opinionated review short and just focus on the recent few innovations since transformer model architecture.

Transformer Architecture
The 2017 paper "Attention Is All You Need" introduced the Attention mechanism, which allows the model to focus on different parts of a sequence to effectively complete the task. For example, if the model is given the sentence "he walked to her home" and asked to classify the gender of the main character, the Attention mechanism would give more weight to the word "he". The below diagram shows the encoder part of the encoder-decoder transformer architecture in that paper.

Mixture of Experts (MoE) Architecture
Mixture of Experts (MoE) architecture then emerged, which created a sparser network with specialized segments called experts. Rather than updating the parameters of one large feedforward network, a subset of many smaller feedforward networks is updated. This decreased the computational requirements during both training and inference, allowing for the training of larger networks with more data. Below figure shows how the feed forward network in the transformer’s decoder (highlighted in blue) was broken down into multiple smaller FFNs in MoE.

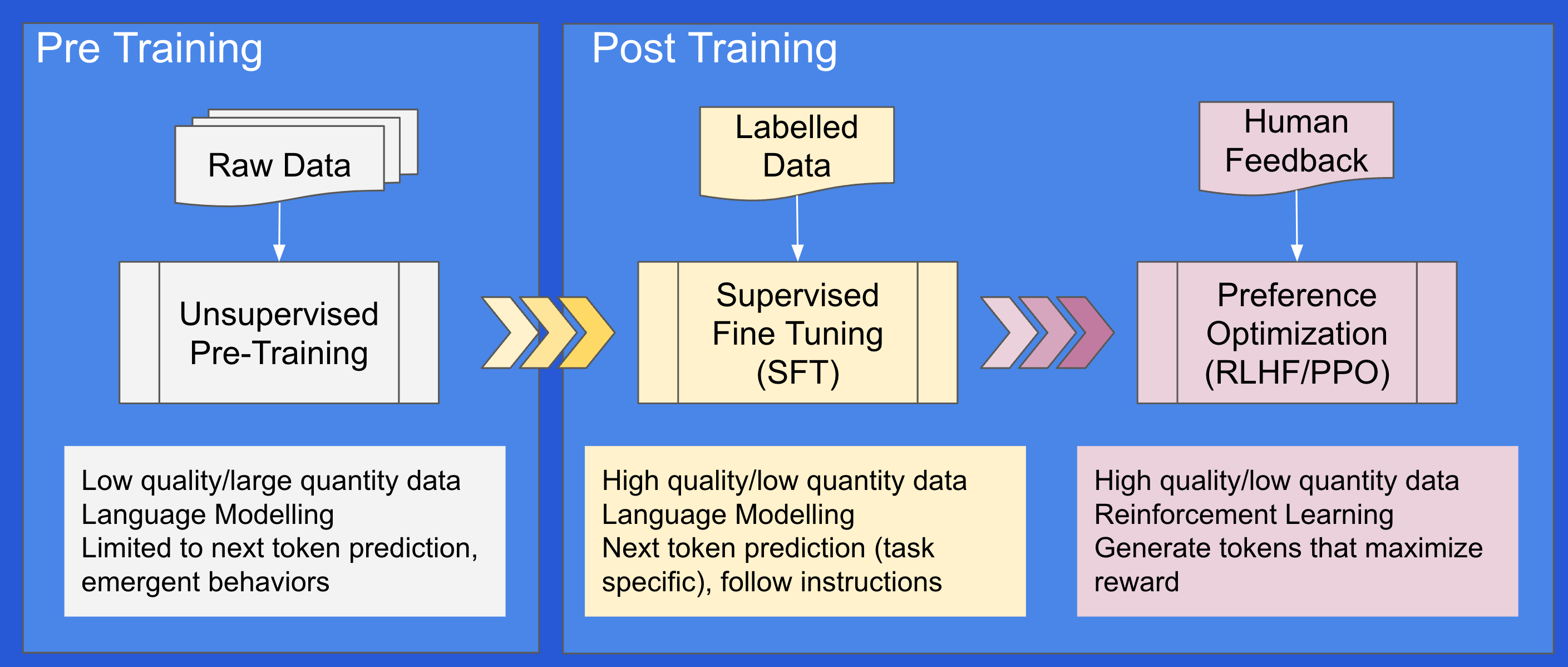
Two Stage Training Pipeline - GPT, SFT and RLHF
The next big step was in the training methodology used to train LLMs. The 2018 GPT paper introduced a two-stage training pipeline, consisting of unsupervised Generative Pre-Training (GPT) on massive datasets followed by Supervised Fine Tuning (SFT). In some sense, the true birth of generative AI revolution was marked by this paper. The InstructGPT paper from 2022 then added a third step: Reinforcement Learning From Human Feedback (RLHF). This step uses human annotators to score the model's output and then fine-tunes the model further, ensuring alignment with human expectations.
Chain of Thought
The focus then shifted to post-training or test-time improvements with prompt engineering, specifically Chain of Thought reasoning. Chain of thought prompting decomposes complex tasks into a series of logical sub-tasks, guiding the model to reason in a human-like manner. Finally, ChatGPT was introduced as a user-friendly chat interface.
Scaling Laws
The last stop on our tour is scaling laws. This theoretical innovation provided the framework that shifted industry focus from pre-training to post-training and finally to test-time.
The 2020 publication Scaling Laws for Neural Language Models introduced the concept that LLM performance improves with increases in model size, dataset size, and compute used for training. This spurred a focus on scaling:
Initially, pre-training scaling was the focus, with efforts to increase the size of models, pre-training datasets, and compute clusters.
When the limits of internet data were reached, the focus shifted to post-training scaling, using Reinforcement Learning with Human Feedback (RLHF) and Supervised Fine Tuning (SFT). High-quality, human-annotated, task-specific data for fine tuning became a key differentiator for many companies.
As post-training gains diminished, test-time scaling came into focus, using prompt engineering and Chain of Thought reasoning.
Enter DeepSeek
The previous section highlighted that the industry was more focused on scaling these past few years, rather than model architecture or training methodologies. This is changing with DeepSeek’s announcement of its R1 model on January 20, 2025. US export restrictions on China seemingly limited scaling as an option to improve LLMs, forcing innovation across multiple aspects of model building, which can be categorized into three areas.
Model Architecture
DeepSeekMoE with Auxiliary-Loss-Free Load Balancing
Only 37 billion parameters activated out of 671 billion for each token
MLA - Multi-Headed Latent Attention
Compressing key/value vectors using down-projection and up-projection matrices for more optimal memory and compute use
Multi-Token Prediction Training Objective
Predicting more than 1 token at a time, again optimizing compute
Powers speculative decoding during inference to speed up inference
Training Methodology
Direct Reinforcement Learning on the Base Model
No supervised fine tuning (SFT)
Surfaced emergent CoT behaviors - self-verification, reflection etc.
New Group Relative Policy Optimization (GRPO)
Estimates from group score instead of using critic model
Rules based reward with accuracy and format rewards
New Four Stage Training Pipeline for Final Model
Cold start data
Reasoning oriented RL
Rejection sampling and SFT
RL for all scenarios for alignment
Distillation of Reasoning Patterns
Data generated by DeepSeek-R1 used to fine-tune smaller dense models like Qwen and Llama
Training Framework
FP8 Mixed Precision Training Framework
Previous approaches of Quantization were about converting the weights form FP32 to FP8 after model training
DualPipe Algorithm Pipeline Parallelism
Bidirectional pipeline scheduling and overlapping communication with computation
Reduces pipeline bubbles and communication overhead introduced by cross-node expert parallelism
Near-zero communication overhead while scaling the model and employing fine-grained experts across nodes
Better Utilization of InfiniBand and NVLink Bandwidths
Improved cross-node communication
20 of the 132 processing units on each H800 specifically programmed to manage cross-chip communications
Memory Optimizations
Selective compression and caching
Conclusion
This concludes our first post in this three part series on DeepSeek. We explored the past few years when scaling laws drove the industry to focus on scaling datasets, compute, and model size to enhance LLMs. We briefly discussed key innovations - Transformer architecture, Mixture of Experts architecture, 2-stage training pipeline, prompt engineering, and Chain of Thought - that facilitated this scaling. Additionally, we did a quick review of DeepSeek's innovations, given their scaling limitations due to export restrictions. The technical details of these innovations are explored in detail in these two posts: